Base-122 Encoding
A space efficient alternative to base-64. [GitHub repository]
§1 Overview
As a binary-to-text encoding, base-64 inflates the size of the data it represents by ~33%. This article presents base-122, a UTF-8 binary-to-text encoding which inflates the original data by only ~14%. Base-122 was created with the web in mind. The implementation includes a small Javascript decoder to load base-122 encoded resources in web pages.
Disclaimer
As §3 shows, base-122 is not recommended to be used on gzip compressed pages, which is the majority of served web pages. Base-122 may however be useful as a general binary-to-text encoding.
§1.1 Introduction
External binary resources like images, fonts, audio, etc. can be embedded in HTML through base-64 encoded data URIs. A typical use is to embed small images to avoid HTTP requests and decrease load time.
<!-- This requires an extra HTTP request to fetch "example.png". -->
<img src="example.png" />
<!-- The same image embedded with base-64 encoding -->
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGYAAABmCAMAAAAOARRQAAAAkFBMVEX////MAADLAAD//Pz+9/f66en+9vb/+vrPAAD88PD21tb439/109P65OT32tr87e3yxMTWRkbSLy/YT0/pnZ3rp6fxv7/QJSXkf3/genrmlZXwurrPHh7eYmLzycnebW3jhYXODg7tsbHaVFTVPT3kjY3PFBTfc3PVPz/WSkrcXl7bZWXSIiLssrLooaHWNTXt35LZAAAGB0lEQVRoge1a55aiShCGIhgIoiIoMkgQMfv+b3erqkG5s3Nm5yzl/to6Z5wGtT8qh1bT/tE/egOZs78AcqubSx167wWxqgKQ9EXyThR/Dzqh4MvSfxuKt0SU+FLpBPTI5Da26+h1YeSIsvNn3vZIOAtXDGUDcfC8GuHeFa+8E+GcpVB2JKSncFZ4pYzZnyNMJYSiTT7ooefT9nINcOBFQMysDSkYzTozjt/B6GP6H8XI1sYUQ0Gx7Qnn5HcwgJwFB7KE9gM3SwTHexDOkY2qxO1PxjbFO033NlwmIjjTOeM4uLRwVTSEux6pN40dQD6SwWEnqWzclBHxL7Tb97YHHRIhU3AWtPsFTTnCBS5X3TvuAuAoFnQ8toOLpdlrwhm7rZhcsoWtFAo/teLHYQHqeYbW7JRXRKnlUFAHMePYmj8mfjB8bpoT4sFZRv8dRQfGmWjOQeUBSgcAOxlrnviuO+VMGV2JjbWpTfJFiwGPu4yRlTt89vExIWPaLhgHV1myPBR6WoUyicDO2UnwZb8yOv0Qjub5SDJRRjPWCoNfKFCuOGkKBmamFe2fVnudgZaIEyoc+/ff/TlZ5JO7yHNXc8bJ0ahCMmfIJWE8YEdBmp05xlCISZi1UAzE1O5oY50acmKiIMMiuYFeCqFE19sKXtIZ5XpXbSRyTqmtHjC+ADjPGyw3YBPOxVB8tmJd723nF3obJieRkMNoWsW2VfQtt0adzKX2b2m0I2bG/erVxhuxMExboKW9oGWgG4nDaBYXNI8XjhEDLMR2v58eu4AKvREnzPQpN/LWDyGUgFMJ7CjDWGQHsGyN2kYpQvDtl39MWaEMWbVInsLhpOZs5JiZLdtWrN3cYrmdLWu72ZOihCqlkFqj/EK1K3xQgzEqurSPdHZ+u8GPaIKF6pEqcS6SPigEuHslRb2Y11JdOrZGBdeTGVcxDcWUjHGKMpPrZ7FL3qtwFXCN1DA/vMyFErM9m03cI3RtXsD8nElODqtqJyKyYJcW18sDLt2NSFWZxIR7fLI2jMz7uLWmJ4wWsZElVLpGzE8zuNAo9dae+h14wPe4dylZP0N7zSl5YUza0NNeF6GqMlb+thDAuVMrGWwvtFX8wjFC6l6OLKuSW+dB6jEr4I7P+owzCvXn/KdMuU77Y5oZJlbjPF+wOJXpvZSZxM8As6qHuI67P6BjjNUFjU4whPX0I+SVQYpNyvVZSthqdiI2WOqInbCXSCzmR643bslVneQrX6lUdhWrxFqaqoz/8nBnyfY2/eY7f0IqkvRcwuEZwFwoh3VkbOETjjsHNdKQoElZRyp43BinfvX30zm7qwBZa0rx45L9ggdX/WmFvxYB0Zy5GvG0w6NbShehcOuq+ad2XoWBnmW15bUwDpWTcFheXwmFmz4RHPO1BRWQG7SkunjpPik+6efPKMuf3S+mRWho71HIOuEzBTPhcDCsdbUTDF7doy4BYuUVs+rZiCsciId4pV/xwOjOFze9G+iZdWsHioccTXwIN0FBIPFOxXcsWbg+pnMFiJuU2nzkx/S0+rD6dp/viaIwFOtnb3JXUqKSooi0nEuaMKgXwSwbYGlTOtiJ3V5VsmUFeMjHrc2YWNJgxzckjJlkvl/NCzbdnPrctk7Nr5/5OWF13zZcn+4v4KrkWHLvBPshKHTkot+/uH8HOCnrvWDrdF7Wg47+RjXo1+jX+zaaWcWp2Ehh7s28YXFmhNEq7Z+OGSMkTDcN6pwrMsRbDz6JMWjUsmkf1fLd/GNRpMvQ58O4czaz0EV1gfF7yfW26zlZGZ6vXbu6iHiQebic9KeOBtGUhiL6Yzl/tL24st5Drc5IoIudQylUebKFgHYFRbJoR79CGTnvmCCAR9VszgdVwpIMx3Ops2XjrgYxcKiSW4ZGPCu5BrTsoCy3gvWYl93DsJw6VuccWdE/Unof0eGskE6+I/Kmtx74K2oQRryL+ZWoHBc9UPiScunzhK/ITGhu9ubffGhegyVI8WZztpPjO46U/kem01BpBvp7fWaqOtr9uwPAluLnx/s9psQW7f0Og3Ym+QuMfzSA/gP09FnS+GSFqAAAAABJRU5ErkJggg==" />
Using the embedded data URI avoids the extra HTTP request to fetch "example.png" from the server. This can improve load time in some cases. It has been recommended to use data URIs cautiously. They may help for small images, but could hurt performance otherwise.
Before discussing how base-122 improves upon base-64, we will briefly discuss how base-64 works. The Wikipedia article gives a much more in depth introduction, but we will cover the main points.
§1.2 Base-64 Encoding
Base-64 is one approach to solving the more general problem of binary-to-text encoding. For example, suppose we want to embed the single byte 01101001 in a text file. Since text files may only consist of text characters this byte needs to be represented by text characters. A straightforward way to encode this byte is to map each bit to a text character, say "A" to represent a 0 bit and "B" to represent a 1 bit. For the sake of example, suppose this silly encoding did exist and that single byte 01101001 represented a (very small) image. The corresponding data URI in HTML could look as follows.
<!-- A toy binary-to-text encoding. -->
<img src="data:image/png;sillyEncoding,ABBABAAB" />The encoding is certainly easy to decode, but only at the cost of wasted space. Each text character "A" or "B" takes one byte in the HTML file. This means we are encoding one bit of binary data with eight bits of text data, so the data inflation ratio is 8 : 1.
Base-64 encoding is an improvement of our silly encoding. It maps chunks of six bits (representing the numbers 0-63) to one of 64 characters. Each resulting character is one byte, so the inflation ratio is 8 : 6.
<!-- The same byte encoded in base-64. The extra == is padding. -->
<img src="data:image/png;base64,aQ==" />Base-64 works well as a binary-to-text encoding since the characters it produces are standard ASCII characters. But to improve upon base-64, we'll have to investigate how much data we can cram into UTF-8 characters.
§1.3 Text Encodings and UTF-8
Since the majority of web pages are encoded in UTF-8, base-122 exploits the properties of how UTF-8 characters are encoded. Let's first clarify some of the terminology regarding UTF-8 and text-encodings.

A code point is a number representing (usually) a single character. Unicode is a widely accepted standard describing a large range of code points from the standard multilingual alphabets to more obscure characters like a coffee cup at code point 0x2615 ☕ (often denoted U+2615). See this Unicode table for a reference of code points.
A text encoding on the other hand, is responsible for describing how code points are represented in binary (e.g. in a file). UTF-8 is by far the most common text encoding on the web. It has a variable length encoding and can represent 1,112,064 different code points. Code points representing ASCII characters require only one byte to encode in UTF-8, while higher code points require up to four bytes. Table 1 below summarizes the format of UTF-8 encodings of different code point ranges.
| Code point range | UTF-8 Format (x reserved for code point) | Total Bits | Bits for code point | Inflation |
|---|---|---|---|---|
| 0x00 - 0x7F | 0xxxxxxx | 8 | 7 | 8 : 7 |
| 0x80 - 0x7FF | 110xxxxx 10xxxxxx | 16 | 11 | 16 : 11 |
| 0x800 - 0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 24 | 16 | 24 : 16 |
| 0x10000 - 0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 32 | 21 | 32 : 21 |
Inflation is the ratio of the character bits to the code point bits. The ratio of 1 : 1 effectively means no waste. The inflation ratio worsens as the number of bytes increases since less bits are reserved for the code point.
§2 Improving Base-64
The encoding of a UTF-8 one-byte character in Table 1 suggests that we can encode seven bits of input data in one encoded byte as in Figure 2.

If the encoding of Figure 2 worked, it would improve the 8 : 6 inflation ratio of base-64 to 8 : 7. However, we want this binary-to-text encoding to be used in the context of HTML pages. Unfortunately, this encoding will not work since some one-byte UTF-8 characters cause conflicts in HTML.
§2.1 Avoiding Illegal Characters
The problem with the above approach is that some characters cannot be safely used in the context of an HTML page. We want our encoding to be stored in format similar to data URIs:
<img src="data:image/png;ourEncoding,(Encoded data)" />Immediately we see that our encoded data cannot contain the double quote character or the browser will not properly parse the src attribute. In addition, the newline and carriage return characters split the line. Backslashes and ampersands may create inadvertent escape sequences. And the non-displayable null character (code point 0x00) is also problematic since it is parsed as an error character (0xFFFD). Therefore, the null, backslash, ampersand, newline, carriage return, and double quote are considered illegal in the one-byte UTF-8 character. This leaves us with 122 legal one-byte UTF-8 characters to use. These 122 characters can almost encode seven bits of input data. When a seven bit sequence would result in an illegal character, we need to compensate. This is the idea which leads us to our final encoding.
§2.2 Base-122 Encoding
Base-122 encoding takes chunks of seven bits of input data at a time. If the chunk maps to a legal character, it is encoded with the single byte UTF-8 character: 0xxxxxxx. If the chunk would map to an illegal character, we instead use the the two-byte UTF-8 character: 110xxxxx 10xxxxxx. Since there are only six illegal code points, we can distinguish them with only three bits. Denoting these bits as sss gives us the format: 110sssxx 10xxxxxx. The remaining eight bits could seemingly encode more input data. Unfortunately, two-byte UTF-8 characters representing code points less than 0x80 are invalid. Browsers will parse invalid UTF-8 characters into error characters. A simple way of enforcing code points greater than 0x80 is to use the format 110sss1x 10xxxxxx, equivalent to a bitwise OR with 0x80 (this can likely be improved, see §4). Figure 3 summarizes the complete base-122 encoding.

This uses one-byte characters encode seven bits and two-byte characters to encode fourteen bits. Hence this attains the goal of encoding seven bits per byte, i.e. the 8 : 7 inflation ratio. Consequently a base-122 encoded string is about 86% the size of the equivalent base-64 string.
§2.2.1 A Minor Note on the Last Character
The last seven bit chunk of input data is padded with zero bits if needed. Therefore, an ending one-byte character can have an excess of up to six padding zero bits. Since decoding rounds down to byte, these six padding bits are conveniently chopped off during decoding. If however, the ending is a two-byte character, we may have an excess of up to thirteen padding bits. This was resolved from helpful suggestions to distinguish whether the last two-byte character encoded more than seven bits.
§2.3 Implementation
An implementation of base-122 encoding and decoding functions is available on GitHub. It provides two main functions:
- Re-encode base-64 strings in file to base-122 with a NodeJS script
- Decode the base-122 strings to the original data with a client-side Javascript function
§2.3.1 Encoding into Base-122
Base-122 encoded strings contain characters which did not seem to play well with copy-pasting. To avoid having the user copy-paste, a NodeJS script is provided which re-encodes base-64 data URIs inside an HTML file. Figure 4 shows an example.
<html>
<head><meta charset="utf-8"></head>
<body>
<img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCj/wgARCABAAEADASIAAhEBAxEB/8QAGwAAAwEAAwEAAAAAAAAAAAAAAgQFAwABBwb/xAAUAQEAAAAAAAAAAAAAAAAAAAAA/9oADAMBAAIQAxAAAAH03tUhvpURrqbmVwmEeVUx0H1F2Roebiab6BzCQ6POQ6gzmpWJFN2efDMTTGt09ivuahWOcZ//xAAgEAACAgICAgMAAAAAAAAAAAACAwABBBIREwUhFCIz/9oACAEBAAEFAuZzOZtN5vOam1TebzeWdVLyVwstNT5C53hKe+yU4jhbBLaXNjc1Hc7UNtMBmwLFTrMbd1iqylWUMhKmLW2XhDSlsHqr8R0ZPsoBtV3m8ioHtqZJEsBIqAW0MLIKonPyahPPKbqfYPuZgbFbIJ+jZtEHrGEZUlrKYfkmnBzN7KDfFbXUWVXaLX1NNQ3ju1jyQVf/xAAUEQEAAAAAAAAAAAAAAAAAAABA/9oACAEDAQE/AQf/xAAUEQEAAAAAAAAAAAAAAAAAAABA/9oACAECAQE/AQf/xAAsEAABAwMBBgQHAAAAAAAAAAABAAIREiExIgMQMkFRYRMjcZEwM2JygaGx/9oACAEBAAY/Avh3IXEuML5jfdcbfdaSVTS6vsgCdR5SuDaInH7WpsrWtBYV3hOIAkWEqk88TdAsNzzRL3ymm0fSpo9iqnNv6oUCrrIVUGG80Bl56Knwtp+VFLgSmDZVZWb/AGoPrZULwolCaqVo8v8Aq5PHogTFkzAMY6q7VgkbsbrWKY5oLR1Q2wN22QqvCii/ffjc1xyOq8qpqccg8iFbZmexX//EACAQAQACAgIDAQEBAAAAAAAAAAEAESExQVFhcYGRsdH/2gAIAQEAAT8h9oZbhLTiUlGPdGB6z5nxBLAeYFyZQ3n6l+f0pDh/NK0rwxK1rQpfogwUsKBB4xuIVrwigcS/cKAR6OI+4HNLxC2qtGdwGnnFs1+7bBOEJo8RiNR5qp5k2Fe4XVBzsjTOZOsHvZS0S9OGY/2WK3EAf7N1+1D11K9DTPwmgZj24uz/AGOLEpiR06hoZXlZsO5hd2dZRrKb2x8mS4K8dxLf7Xv6gwyByZl6DHHEQTuWrCMi/UVt6NVKih0ZYZ7DcNqosWwa6wduYXEbQ/kAZhDgxNwN2xFDY5Bx8i4Jv7EGp881VP/aAAwDAQACAAMAAAAQ48AQocYogYQw8wks/8QAFBEBAAAAAAAAAAAAAAAAAAAAQP/aAAgBAwEBPxAH/8QAFBEBAAAAAAAAAAAAAAAAAAAAQP/aAAgBAgEBPxAH/8QAJRABAQACAgICAQQDAAAAAAAAAREAITFBYYFRcZGhscHREOHx/9oACAEBAAE/ELXZc5C3B8rg9jiIrT1gqA+9YM4XPkfp/jCyt7GedtKYiNPuMzaAqAFcBgEWaP3Y82fpv5whWuuBytDmRuXOodKOZTd+cb421wPG/wCckzcw6PnVMAggjWBDYTduP4psU/V4xRdiqKuqcv4zpLF83etTHZmwLtUSPZ3h6mQYg7Nt/wCYYTQmjRuF47wmlq5ke9bywDAyijpL8T8ZydQaKhCiz6wvlGERWU71Mh634Rny6Uxvdh3g54jxOJiS6hxfT9uLhawWowu4NemJ0Q0KV5xM5HoALv8AP7YdFuGrfsFycbgcpu70/wCsKDqCtvxmpUb6gpX43MlhCAz0bV4MvigFhHsN45XDAiKpn0frhHC7geRAqyHPjKoI9gNehx2EggXT1j+pyGfGRQHGr7x0r0msWFcV3P7/ALxYepTu6buzrG4wB2SS66DHNZ46PL9HNyZBMRKNh+MLGqbwJSF57YAIeU3idMCqa5xThyDanSX6zbFXkT8rkPDcLTjx+22H35xRJaj+kRz/2Q==" />
</body>
</html>
<html><body>
<head><meta charset="utf-8"></head>
<body>
<img data-b122="v ~ J#(` m@0 @0ƆA``@( ƅ!PP
q `0ƅBaPtJ ʆd1`X, 21
R*F#ri@Z( %I#[`8
ƄB0P(ҨʅCρ P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅGBÈ@D@?| ¶à A`o~À 4à S=UoRQʺMf+B0GJTcP>Q;Py֦MzLGN!j9TVngOCMk:=E>s(+8g| À@ ΰ)(Ι{ Pf9MS<o
j6Tofy3U%r+BeS)yg<O>dSD8-Ai9Xn5sZC6L1)kmnXU2JY!H%Җ[2x!RK0=*~hd}Jí+^7HT[)I(m
*DsyB<yӵ 0>s˅6 Ohlm
Xa
TK,Srӎ^e>Zu
.hZ}Ӎ!^
m1r U| ¨À~hÀ` |q D ?{ À'p DÁ@@8 DD
H
ң8d҃ ePl?}PÀãx
pw֥cyF}kFo]4I*4]/YT<R֍Q c{-ӥ5VA0W<DÈX%)
<ӴC9sί>)S4>JM1*N6*ƂW,BUyP
^=ǏBm JE`lU2Y_p( -JBx(J U%4<_p.'GQY@cU.j`Hnc:kƱfA4:Pm@nmH*^Ɣ/o_Fs.
G*y*M' y+63
b_qÀÀ À EQ0ְˇ#m H>h2n 4qJ{Q@zgf>%@<`.Ҩ7Oj/gz)yRZ+aDVZh)?ΆƂFDWB ?8(
G}`9RxBm*hg8O
-M?;6pB4<#j
5)s0W֗*
HiN2:`{lRhKiaL?lXVqv7/m!uj+h4gpML=֮g|ãEDS NPh2^+9Bw3V(ko6 p+c֥_v^(2IL^AG;K+2uǭt5)(Pt2aO0n˕Ϣlʺ`vsb!~ 0CADn;1ƍG8|E`M~bSsfU'4àPqE
asK | ¨À~hÀ` | q D ?{ À'qDÀ Ҕ
Q8d4ΐp|?}PÀxBkY9dp>+Av
ΕSkP^Xa9yi
+=F<viґʟ8f6@*`4?; S?N+.ևPsלu%2Mog˸mWq_prҷ:
)@ FX6 ]ֿEƿ+cƗ1*:SK|3R,/Mo-ҝLlm(H{
pzLADfm@ PMʍa<;a-.2
zoà2EI? |3IjE!
,e
ǥ
uV~geiқnaoOxN (8_'vq8-0-#n^L'sDgt?`}X:pjol
Ic8)]o'|,P+7qM%#>P)/c9I0BO#5<
_ƀX#lcJp`ΕҾGua
ևH@UH9xe(vWPqliuGzN!OFπ8j}qi/$k
8W9~@ECj)ntnv:c8`2$]:
k
t9ADQX?
S<R
g[
)^S*5gƸ95
~Y[Ǟοd
ˡ4qq}[0}|qΥT?Rg2" />
</body>
</html>
A few points are worth noting. Only data URIs in an src attribute are re-encoded, not CSS data URIs. The meta charset tag with a UTF-8 charset must be specified. The data-b122 attribute is used for easy querying of the DOM during decoding. The default mime-type is "image/jpeg" but a data-b122m attribute is used to specify other mime-types.
§2.3.2 Decoding into Blobs
To decode the base-122 encoded resources, we need to provide an analog to the atob function to decode base-122 strings back to the original data. We also need to include some setup code (i.e. querying the DOM and creating decoded blob URLs with createObjectURL). Including these scripts in the HTML page means either adding an external script (adding another HTTP request) or including the full function in the page. Unfortunately, this erodes the space savings from base-122 encoding. Therefore, our decode function should be as small as possible without sacrificing performance. The minified decoding script is shown below, currently sized at 487 bytes.
// Decodes all elements with a data-b122 attribute and creates blob URIs.
!function(){function t(t){function e(t){t<<=1,l|=t>>>d,d+=7,d>=8&&(c[o++]=l,d-=8,l=t<<7-d&255)}for(var n=t.dataset.b122,a=t.dataset.b122m||"image/jpeg",r=[0,10,13,34,38,92],c=new Uint8Array(1.75*n.length|0),o=0,l=0,d=0,g=n.charCodeAt(0),h=1;h<n.length;h++){var i=n.charCodeAt(h);i>127?(e(r[i>>>8&7]),h==n.length-1&&64&g||e(127&i)):e(i)}t.src=URL.createObjectURL(new Blob([new Uint8Array(c,0,o)],{type:a}))}for(var e=document.querySelectorAll("[data-b122]"),n=0;n<e.length;n++)t(e[n])}();
Figure 4c shows the final HTML file with the decoding and setup code.
<html><body>
<head><meta charset="utf-8"></head>
<body>
<img data-b122="v ~ J#(` m@0 @0ƆA``@( ƅ!PP
q `0ƅBaPtJ ʆd1`X, 21
R*F#ri@Z( %I#[`8
ƄB0P(ҨʅCρ P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅGBÈ@D@?| ¶à A`o~À 4à S=UoRQʺMf+B0GJTcP>Q;Py֦MzLGN!j9TVngOCMk:=E>s(+8g| À@ ΰ)(Ι{ Pf9MS<o
j6Tofy3U%r+BeS)yg<O>dSD8-Ai9Xn5sZC6L1)kmnXU2JY!H%Җ[2x!RK0=*~hd}Jí+^7HT[)I(m
*DsyB<yӵ 0>s˅6 Ohlm
Xa
TK,Srӎ^e>Zu
.hZ}Ӎ!^
m1r U| ¨À~hÀ` |q D ?{ À'p DÁ@@8 DD
H
ң8d҃ ePl?}PÀãx
pw֥cyF}kFo]4I*4]/YT<R֍Q c{-ӥ5VA0W<DÈX%)
<ӴC9sί>)S4>JM1*N6*ƂW,BUyP
^=ǏBm JE`lU2Y_p( -JBx(J U%4<_p.'GQY@cU.j`Hnc:kƱfA4:Pm@nmH*^Ɣ/o_Fs.
G*y*M' y+63
b_qÀÀ À EQ0ְˇ#m H>h2n 4qJ{Q@zgf>%@<`.Ҩ7Oj/gz)yRZ+aDVZh)?ΆƂFDWB ?8(
G}`9RxBm*hg8O
-M?;6pB4<#j
5)s0W֗*
HiN2:`{lRhKiaL?lXVqv7/m!uj+h4gpML=֮g|ãEDS NPh2^+9Bw3V(ko6 p+c֥_v^(2IL^AG;K+2uǭt5)(Pt2aO0n˕Ϣlʺ`vsb!~ 0CADn;1ƍG8|E`M~bSsfU'4àPqE
asK | ¨À~hÀ` | q D ?{ À'qDÀ Ҕ
Q8d4ΐp|?}PÀxBkY9dp>+Av
ΕSkP^Xa9yi
+=F<viґʟ8f6@*`4?; S?N+.ևPsלu%2Mog˸mWq_prҷ:
)@ FX6 ]ֿEƿ+cƗ1*:SK|3R,/Mo-ҝLlm(H{
pzLADfm@ PMʍa<;a-.2
zoà2EI? |3IjE!
,e
ǥ
uV~geiқnaoOxN (8_'vq8-0-#n^L'sDgt?`}X:pjol
Ic8)]o'|,P+7qM%#>P)/c9I0BO#5<
_ƀX#lcJp`ΕҾGua
ևH@UH9xe(vWPqliuGzN!OFπ8j}qi/$k
8W9~@ECj)ntnv:c8`2$]:
k
t9ADQX?
S<R
g[
)^S*5gƸ95
~Y[Ǟοd
ˡ4qq}[0}|qΥT?Rg2" />
<script>
!function(){function t(t){function e(t){t<<=1,l|=t>>>d,d+=7,d>=8&&(c[o++]=l,d-=8,l=t<<7-d&255)}for(var n=t.dataset.b122,a=t.dataset.b122m||"image/jpeg",r=[0,10,13,34,38,92],c=new Uint8Array(1.75*n.length|0),o=0,l=0,d=0,g=n.charCodeAt(0),h=1;h<n.length;h++){var i=n.charCodeAt(h);i>127?(e(r[i>>>8&7]),h==n.length-1&&64&g||e(127&i)):e(i)}t.src=URL.createObjectURL(new Blob([new Uint8Array(c,0,o)],{type:a}))}for(var e=document.querySelectorAll("[data-b122]"),n=0;n<e.length;n++)t(e[n])}();
</script>
</body>
</html>
§3 Experimental Results
To see if base-122 is a practical alternative to base-64 encoding on the web, we tested our implementation to verify the space savings and to check runtime performance.
§3.1 Storage Savings
Base-122 encoding will encode seven bits of input data per byte while base-64 encodes six, so we expect base-122 data to be about 14% smaller than the equivalent base-64 data. An initial test on square images of various sizes confirms this.
| Image (JPEG) Dimension | Original (bytes) | Base-64 (bytes) | Base-122 (bytes) | % difference |
|---|---|---|---|---|
| 32x32 | 968 | 1292 | 1108 | -14.24% |
| 64x64 | 1701 | 2268 | 1945 | -14.24% |
| 128x128 | 3027 | 4036 | 3461 | -14.25% |
| 256x256 | 7459 | 9948 | 8526 | -14.3% |
However, as pointed out in this article, gzip compressing the HTML page significantly reduces the size of base-64 encoding. Table 3 shows the results of encoding with the gzip deflate compression applied.
| Image (JPEG) Dimension | Original (bytes) | Base-64 gzip (bytes) | Base-122 gzip (bytes) | % difference |
|---|---|---|---|---|
| 32x32 | 968 | 819 | 926 | +13.06% |
| 64x64 | 1701 | 1572 | 1719 | +9.35% |
| 128x128 | 3027 | 2914 | 3120 | +7.06% |
| 256x256 | 7459 | 7351 | 7728 | +5.12% |
Unfortunately, base-64 seems to compress better than base-122, which may be due to the more redundant sequences of bits in base-64 being easier to compress. Interestingly, using base-64 with gzip compresses it enough to make it smaller than the original.
§3.2 Performance
A point of practical concern for the base-122 decoder is performance. A significant drop of performance of decoding base-122 in the browser could outweigh any benefit gained in load time from the smaller download size. Using this JSPerf test the base-122 decoding function was compared with the native base-64 decoding function atob, on equivalently encoded random binary strings of 10,000 bytes.
| Browser/OS | Base-64 Ops/Sec | Base-122 Ops/Sec |
|---|---|---|
| Chrome 54/Win. 10 | 9,141 | 3,529 |
| Firefox 50/Win. 10 | 2,342 | 5,338 |
Chrome shows about a ~3x drop of performance, while Firefox shows a surprising 1.5-2x improvement.
§3.3 Case Study
For a practical test, we compared size and load time of HTML pages with various amounts of small images. Using 64x64 pixel images scraped from unsplash.it, pages with 10, 100, and 1000 images were compared.
First, we verified the download size of each page was as expected.
Next, we measured the load time over five trials and recorded the median in both Chrome and Firefox.
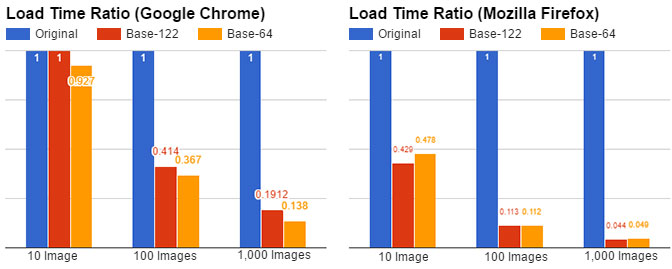
We see a marginal improvement in Firefox, but an unfortunate regression in Chrome. This may be due to a variety of reasons, including the delay of decoding base-122 data until the decoder script is parsed and loaded, while base-64 strings can be decoded as soon as they are parsed. Furthermore, with gzip enabled, we no longer get any improvement in download size. These tests suggest base-122 may not have much use in the context of the web, at least not without help from the browser.
It is worth noting that although both base-64 and base-122 improve load time, externally loading images still has the advantage of progressive loading. I.e. by not embedding the image data, parts of the HTML page can load before the image data downloads.
§3.4 Replicating the Results
You can replicate these results or test in different environments as follows
- This NodeJS script is used to compute the size differences in §3.1
- The JSPerf test can be run in any browser supporting TextDecoder
- These NodeJS scripts were used to scrape unsplash.it and generate pages with variable numbers of 64x64 pixel images.
§4 Conclusion and Future Work
Although improving performance on the web was the purpose of base-122, it is not limited to the web. Base-122 can be used in any context of binary-to-text embedding where the text encoding encoding is UTF-8. And there is still room for improvement, including but not limited to:
- Encoding an additional bit in the two-byte UTF-8 characters by using the illegal index to enforce code points above 0x80
- Improving decoding performance for browsers, or making it non-blocking via web-workers
- Further reducing the size of the decoding script
Contribution and critical feedback is welcome and encouraged on the GitHub page.